8.3 Naming Organic Compounds
Learning Objectives
- Explain the importance of having a standard naming system in organic chemistry.
- Understand the main guidelines for naming an organic compound using IUPAC nomenclature.
Video 8.3.1: Organic Nomenclature. Explanation of organic nomenclature in chemistry. Video attribution: “Organic Nomenclature” by RMIT Library. © 2024 RMIT Library, licensed under CC BY-NC-SA 4.0.
Chemists commonly use drawings and names to communicate about organic structures. While names are preferred in certain situations, the vast number of known organic substances makes naming each one independently impractical. To address this, the International Union of Pure and Applied Chemistry (IUPAC, usually pronounced eye-you-pack) has developed a naming system. This system allows for the description of a chemical by components of a name, providing enough information for a complete and unique structure. Although the IUPAC system is frequently used for simpler molecules, more complex substances, especially those produced by biological organisms, may have lengthy names.
How to get a systematic name from a structure
- To assign a name to a compound, begin by determining the parent chain, which is the longest straight chain of carbon atoms. We’ll start by considering the simplest straight-chain alkane structures.
If the parent chain is just one carbon long, the name is based on [latex]\ce{CH_{4}}[/latex], which is called methane. For a two-carbon parent chain, the name will be based on [latex]\ce{C_{2}H_{6}}[/latex], which is ethane. Figure 8.3.1 displays the prefixes used in naming hydrocarbons (1, 2, 3, etc., means the number of carbons present in the longest continuous carbon chain.)

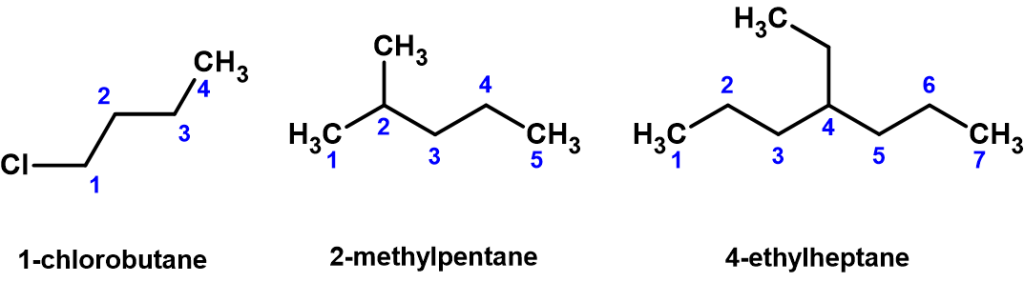
- Substituents branching from the main parent chain are given a location signifier. This is done by providing the counted carbon number within the parent chain where the branch exists, with the lowest possible numbers being used. For example, notice below (Figure 8.3.2) how the compound on the left is named 1-chlorobutane, not 4-chlorobutane. “1” designates the chlorine is attached to the first carbon in the parent chain. When the substituents are small carbon-containing, so-called alkyl groups, the terms methyl, ethyl, and propyl are used to identify them.
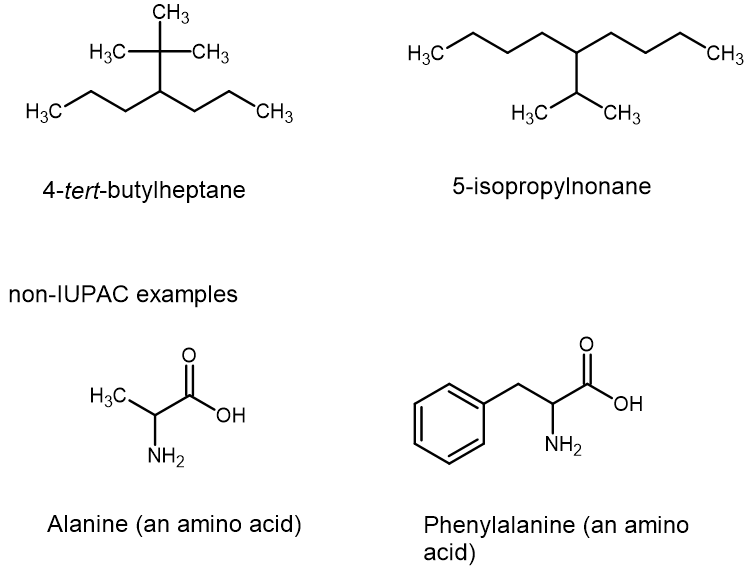
Other common names for more complex alkyl groups are isopropyl, tert-butyl, and phenyl, as shown in Figure 8.3.3. You may recognise how complicated the names could become, with multiple branches and non-carbon substituent groups all possible on large chains, etc. In some situations, this has caused a preference for common names to be used in casual talk or even among scientists, such as the names given for the amino acids shown in Figure 8.3.3. Some common names, such as phenylalanine, include components of systematic names within them. No one can learn all the common names, and no one can learn all the rules for systematic names in a short period of time. For now, we are learning bits and pieces, and learning how the system for nomenclature works.
- The structure shown in Figure 8.3.4 is laid out on the page so that the longest continual carbon chain is oriented vertically. Structures that are presented this way can be confusing, leading to misinterpretation. In this case, the structure could be accidentally named 2-ethylpropane (incorrect) instead of 2-methylbutane (correct).
Keep in mind the IUPAC name for straight-chain hydrocarbons is always based on the longest possible parent chain, which in this case is four carbons, not three. Especially if you are looking at large and complicated structures, it can get tricky to identify the parent chain, but it is the foundation of the name.

When carbons bond to form rings, the resulting cyclic alkanes are called cyclopropane, cyclobutane, cyclopentane, cyclohexane, and so on (Figure 8.3.5):

- In cases where multiple copies of the same substituent are on a structure, the prefixes di, tri, and tetra are used. For instance, if there are two methyl groups present, we name it ‘dimethyl’, and the presence of three fluoride atoms will be named ‘trifluoro’ (Figure 8.3.6).
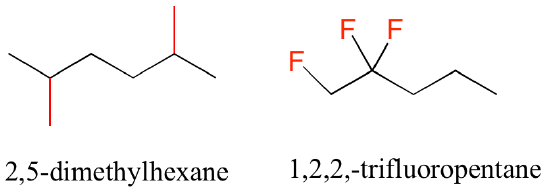
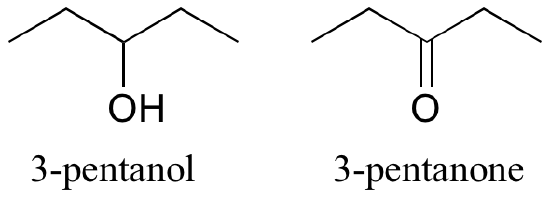
- We will learn more about functional groups soon. But for now, it is important to highlight that these recognisable groups of atoms show up in names as characteristic suffixes. Alcohols, for example, have ‘ol’ appended to the parent chain name, along with a number designating the location of the alcohol group (Figure 8.3.7). Ketones are a functional group with a double bond to oxygen, designated in names by the suffix ‘one’ (Figure 8.3.8). For alkanes, the suffix would be ‘ane‘.
- All of the examples we have seen so far have been simple in the sense that only one functional group was present on each molecule. There are, of course, many more rules in the IUPAC system, and as you can imagine, the IUPAC naming of larger molecules with multiple functional groups, ring structures, and substituents can get very unwieldy very quickly. The drug cocaine shown below in Figure 8.3.8, for example, has the IUPAC name ‘methyl (1R,2R,3S,5S)-3-(benzoyloxy)-8-methyl-8-azabicyclo[3.2.1] octane-2-carboxylate.’
![A line-bond structure and the IUPAC name for the compound known as cocaine: (methyl(1R,2R,3S,5S)-3-(benzoyloxy)-8-methyl-8-azabicyclo[3.2.1]octane-2-carboxylate. The structure has many substituent groups.](https://rmit.pressbooks.pub/app/uploads/sites/67/2023/09/fig1-2-30.png)
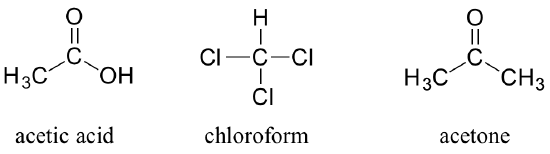
You can see why the IUPAC system is not used very much in biological organic chemistry – the molecules are just too big and complex. A further complication is that, even outside of a biological context, many simple organic molecules are known almost universally by their ‘common’, rather than IUPAC names. The compounds acetic acid, chloroform, and acetone are only a few examples (Figure 8.3.9).
Key Takeaways
- The IUPAC system is used in naming organic compounds.
- The prefix is based on the number of carbon atoms present in the parent chain.
- The suffix is selected based on the functional group present in the structure.
- Substituents present on the structure should be located and named.
- Biological compounds can have complicated names due to the complexity of their structures.
